前言
本文参考WC2012陈立杰论文,在其基础上作总结与扩展。
简介
后缀自动机(Suffix Automaton,下简称SAM),是可以识别字符串S的所有后缀的有限状态自动机。它也可以用来识别字符串S的所有子串,处理许多字符串的问题。
有限状态自动机
有限状态自动机是一种用于识别字符串的模型。
自动机由五个部分组成,alpha:字符集,state:状态集合,init:初始状态,end:结束状态集合,trans:状态转移函数。
对于自动机A,若S∈end,则称A能识别字符串S,记A(S)=true,否则A(S)=false。
设trans(s,ch)表示当前状态s,在读入字符ch之后,所到达的状态。
那么自动机识别一个字符串S的过程是:从初始状态init开始,对S的每个字符ch依次执行状态转移trans(cur,ch),最终的状态t就是S所在的状态。
设trans(init,S)表示从init开始,在读入字符串S之后,所到达的状态。
字符串S的后缀自动机需要满足的,就是A(trans(init,str))=true当且仅当str是S的后缀,也就是A能且只能识别S的后缀。
SAM与后缀树
事实上,SAM并没有那么抽象或遥不可及。我们熟悉的后缀树就是SAM最简单的实现。
对于字符串aabbabd,建立它的后缀树:
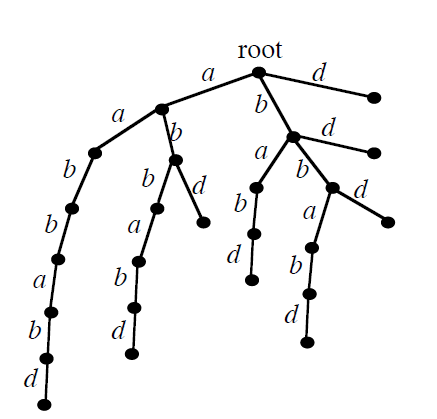
我们可以把它看成一个SAM:状态集合是树上所有点,初始状态是root,状态转移函数是树的边,结束状态是叶子节点。因为后缀树的叶子节点表示的正是字符串的所有后缀,所以后缀树就是一个SAM。
但这样实现的问题在于:时空复杂度过大。尽管后缀树有各种优化,但优化的效果仍不理想,不能达到线性的复杂度,而且代码繁难。
最简状态自动机
最简状态自动机,是指状态数最少的自动机。
通过下文要讲的状态的合并,可以将SAM的状态数优化到O(n),得到最简状态SAM。我们平常使用的SAM,就是最简状态SAM。
SAM上的状态
在讲状态合并之前,首先要明确SAM上应该有哪些状态。
记ST(str)=trans(init,str),即从初始状态开始,读入字符串str后,所到达的状态。
记字符串S的子串集合为Fac(S)。
在刚才用后缀树实现的SAM上,状态集合是{ST(str)∣str∈Fac(S)},其实对于SAM的所有实现都是这样。
因为,SAM的功能是识别S的所有后缀。则SAM上保留的状态,应该是所有有潜力成为后缀(即再读入几个字符就成为后缀)的子串。那么,就应该保留S的后缀的所有前缀,即S的所有子串Fac(S)。
形式化地,ST(str)=null当且仅当str∈Fac(S)。
此时,原串的每个子串对应着一个状态,这就使状态数具有O(n2)的数量级,这是非常不妙的。于是,我们来考虑一下如何对这些状态进行合并。
状态的合并
考虑一下,对于一个状态,我们关心什么。
SAM的最终目的是识别后缀。所以对于一个状态,我们唯一关心的是,它能够识别哪些串。
回顾一下识别的定义:ST(a)能识别字符串b,当且仅当ab∈Suf(ab是字符串a和b连接,Suf是后缀集合)。
那么,可以得到b∈Suf。
设a在原串S中出现的位置为{[l1,r1],[l2,r2],…,[lk,rk]}。那么,ST(a)能识别的字符串b∈{[r1+1,n],[r2+1,n],…,[rk+1,n]}(n是S的长度)。
可以发现,可识别的串与l无关,只与r有关。换句话说,对于一个状态,我们只关心r。
重要定义:Right(a)={r1,r2,…,rk}(即a在S中出现位置的右端点集合)。
那么,对于一个状态,我们只需要关心Right集合即可。这就意味着:
Right集合相同的状态,都可以被合并成一个。
所以,一个状态s,由所有Right集合是Right(s)的字符串组成。
如此合并之后,状态数就大大减小了。事实上,状态数已经减小到了O(n)。至于证明,下面会提到。
状态对应的字符串
刚才说了,状态s由所有Right集合是Right(s)的字符串组成。那么,如何确定这些字符串呢?
设r∈Right(s),事实上,只要给出串长度len,就可以确定一个串[r−len+1,r]。
对于状态s,只有一些符合条件的len,才能使得到的串str=[r−len+1,r]属于状态s,也就是使得Right(str)=Right(s)。
易证,若长度l和r都合法,那么len∈[l,r]都合法。也就是说,合法长度是一段区间。
一个定义:状态s和合法长度区间记为[Min(s),Max(s)]。
Right集合之间的关系
结论:任意两个状态的Right集合,要么不相交,要么一个是另一个的真子集。
这个结论非常重要,是SAM可以达到线性复杂度的基础。
证明如下:
设两个状态为a,b,Right集合为Ra,Rb。
设Ra和Rb相交,取r∈Ra∩Rb。
由于a,b对应的串不可能有交集,则[Min(a),Max(a)]和[Min(b),Max(b)]也不会有交集。不妨设Max(a)<Min(b)。
那么,由于都是从r往前,而且a中的串更短,则a中所有串都是b中所有串的后缀。
这就意味着,b中的串出现的位置,a中的串也必然出现了,即Rb⊆Ra。
又因为两个状态Right集合不可能相同,则Rb⊊Ra,结论得证。
parent树
从上述结论可以发现,Right集合构成了一个树形结构,我们称之为parent树。
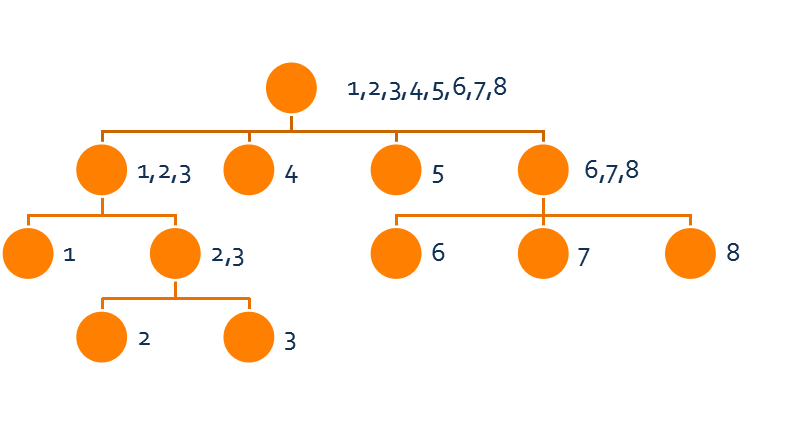
那么,通过“父子真包含”和“兄弟不相交”这两个性质,容易证明结点个数为O(n),也就是说SAM的空间复杂度是线性的。
实际上,parent树上儿子与父亲的合法长度区间[Min(s),Max(s)]也有着联系:
设状态s在parent树上的父亲是fa,s的合法长度区间为[Min(s),Max(s)]。
考虑长度Min(s)−1对应的串str,它不在状态s中,说明随着串变短,出现的位置越来越多,Right(str)已经超出了Right(s)的范围,即Right(str)包含Right(s),而且是包含Right(s)的集合中最小的一个。
根据parent树的定义,str一定属于状态fa,那么Min(s)−1<=Max(fa)。
又因为Right(s)与Right(fa)有交集,那么合法长度就不能有交集(不然会有同时处于两个状态的串)。所以Min(s)>Max(fa)。
综上:Max(fa)=Min(s)−1。
Right集合的存储
SAM上的每个状态,都有一个对应的Right集合。如果暴力存储每个状态的Right集合,空间将是O(nlogn)的。但如果利用我们利用parent树的一些性质,就可以不必直接存储每个结点的Right集合。
如果按照上面那张图,可以发现在parent树上,一个结点的Right集合是其所有子结点的Right集合的并集。
那么,一个结点的Right集合,就可以通过遍历其子树上的叶子节点得到,不必直接存储。
如果得到了某个串的Right集合大小,就可以求出它在原串中出现了几次,这是Right集合最经典的用法。当然这些都是后话。
错误纠正
(以下内容陈立杰论文中没有提到,不保证正确性,请带着批判的眼光阅读或跳过它也没有什么影响)。
回到这张图。这张图过于理想了,很容易误导人,使人感觉parent树的长相都这么好看。事实上,真正的parent树并不太可能长得这么可爱。
首先,Right集合里的元素并不一定是{1,2,3}这样连续的,仍然存在{2,5,7}这样的集合。
还有一点,就是刚才说的“在parent树上,一个结点的Right集合是其所有子结点的Right集合的并集。”这句话是错的。
以字符串aa为例,它有两个子串:a、aa,对应的Right集合分别为{1,2},{2}。而{1,2}在parent树上有且只有{2}这个子结点,元素1缺失了,显然不符合上述结论。
我们来分析一下“缺失元素”的本质。设当前状态为s,缺失元素为r。
缺失元素r,本质就是不存在Right集合为{r}的串。这意味着什么呢?
我们假设存在Right集合为{r}的状态,那么它一定是s的儿子,我们把它记为son。根据前面说的parent树的性质,son状态的合法长度区间为[Max(s)+1,r]。而状态son不存在,说明Max(s)+1>r。对于状态s,显然有Max(s)<=r,于是可得:
状态s缺失元素r,当且仅当Max(s)=r。
由此,我们可以得到“缺失元素”这种情况的一个限制:对于状态s,若其缺失元素,只会缺失Right(s)中最小的r。
证明:
若s缺失两个或两个以上元素,则Max(s)=r1,Max(s)=r2,…相互矛盾。
若s缺失的元素不为最小,设缺失元素r,最小元素为r0。因为Max(s)=r,而Max(s)≤r0,得到r≤r0,矛盾。
故:对于状态s,若其缺失元素,只会缺失Right(s)中最小的元素r。
所以,缺失元素并不会干扰我们之前的复杂度证明。若一个状态缺失元素r,我们只要把缺失的{r}人为补上,就可以得到理想的parent树,上面的证明仍然有效。而补的个数也是O(n)的。
至于Right集合的存储,就要做一些改动:
对于元素r,若存在Right(a)={r},则把元素r放在a上。否则,设状态b缺失元素r,则把元素r放在b上。求Right集合时,只要把子树上放的元素并起来即可。
例如字符串aa,只有状态{1,2}和{2}。所以把元素1放在{1,2}上,把元素2放在{2}上。求Right时只要求子树上元素构成的集合即可。
线性构造算法
经历了艰难的理解过程,终于要进入正题了:SAM的线性构造算法。
在此之前,先明确一点:前文讲的parent树,和SAM的真实结构是两个东西。parent树只是用来辅助构造SAM的。
本文介绍的SAM构造算法是在线算法,也就是从左到右把字符串中的字符一个个加入SAM。
设当前串为T,T的长度为L,要加入的字符为x。
首先,考虑加入x会影响哪些状态。
加入x后,新增了若干个子串,这些子串都属于Suf(Tx)(Tx的后缀)。那么Suf(Tx)对应的状态都要被改动。
另外,考虑哪些串会转移到Suf(Tx):显然只有Suf(T)通过trans(x)会转移到Suf(Tx)。所以Suf(T)对应的转移函数都需要修改。
于是得出结论:添加字符x,需要改动的状态为Suf(T)和Suf(Tx)。而Suf(Tx)可以通过trans(Suf(T),x)得到。所以我们只需要枚举Suf(T)。
设Suf(T)对应的状态(即Right集合中包含L的状态)为{v1,v2,…,vk}。那么,如何得到这些状态呢?
由于此时必定存在Right集合为{L}的状态(串T对应的状态),设这个状态为p。那么由于parent树的性质,所有的v都是p的祖先,可以利用Parent函数(Parent(s)为s在parent树上的父亲)得到它们。
不妨把所有v从后代到祖先排为v1=p,v2,…,vk=root。另外,新建状态np=ST(Tx),则Right(np)={L+1}。
下面要做的事情,就是把状态np插到SAM里去,并且修改ST(Suf(T))(就是所有vi)的转移函数和ST(Suf(Tx))(就是trans(vi,x))的Right集合。
首先,从后代到祖先枚举vi。
上文说过,我们需要修改vi的转移函数,也就是trans(vi,x)。
设当前枚举的v的Right集合为{r1,r2,…,rk=L}。
考虑在后面添加字符x,那么只有S[ri+1]=x的ri满足要求。
若trans(v,x)=null,则说明v中没有满足要求的ri。
但随着v1,v2,v3,…的Right集合逐渐扩大,若vi中有满足要求的r,则vi+1中也有。
所以,trans(v,x)=null的v是从v1开始连续的一段。
一个结论:添加完字符x后,Right(trans(v,x))一定包含L+1。
因为根据定义,状态v包含的其中一个串是T的后缀,再添一个x就变成了Tx的后缀,对应的r=L+1。
所以,对于这些原本trans(v,x)=null的v,显然修改完的Right(trans(v,x))={L+1},也就是说trans(v,x)=np,直接连边即可。
处理完trans(vi,x)=null的vi,我们枚举到了第一个trans(vi,x)=null的vi,称之为vp。
记trans(vp,x)=q。
添加完字符x后,Right(trans(vp,x))一定包含L+1,看似可以把L+1直接插入Right(q)。但其实并不能这样做,以下是反例:

(第一行是vp,第二行是q)。
可以看出,若把L+1强行插入Right(q),则Max(q)被r=L+1的串所限只能取到Max(vp)+1=6,而原来Max(q)=7。Max(q)的缩短将会导致一系列问题,所以我们不能这么做。
(不过如果Max(q)本来就等于Max(vp)+1,则并不会出现什么问题。只需让Parent(np)=q,相当于在Right(q)中插入L+1,就可以结束这个阶段了)。
此时,可以发现q实际上被分成了两段:

(第一行是vp,第二、三行是被分成两段的q)。
于是,我们新建结点nq,使Right(nq)=Right(q)∪{L+1}(对应图片第三行)。同时Max(nq)=Max(vp)+1。
为什么Max(nq)=Max(vp)+1?有没有可能更大?
实际上,因为vp的所有儿子都没有x的转移边,这就说明比Max(vp)更长的T的后缀再接上一个字符x都是没有在T中出现过的,也就是说它们在添加x之后的Right集合一定是{L+1},那么就不会在nq中。
先考虑np,q,nq这些状态在parent树上的关系:
由于Right(q)⫋Right(nq),则:Parent(q)=nq。
同时Right(np)={L+1}⫋Right(nq),则:Parent(np)=nq。
最后,把Parent(nq)设为原来的Parent(q)。为什么可以这么做?
因为q表示的字符串中包含Tx的后缀,设这个串为str,结束位置为r。Parent(q)的Right集合中肯定也包含r,且从r往前的串长度比q短,这就意味着Parent(q)中包含str的后缀(str的后缀同时也是Tx的后缀)。进而Right(Parent(q))就包含L+1。
又因为Right(q)⫋Right(Parent(q)),则Right(nq)=Right(q)∪{L+1}⫋Right(Parent(q)),即:Parent(nq)=Parent(q)。
总结步骤:Parent(q)=Parent(np)=nq,Parent(nq)=原来的Parent(q)。
处理完Parent树上的连边,还要考虑SAM上的连边,也就是转移函数。
注意到在trans(nq,ch)中,nq相比起q多的结束位置L+1是不起作用的(已经到末尾了没法再添字符)。所以nq的转移函数直接从q拷贝过来即可。
处理完vp,剩下的vp+1,…,vk的trans(x)一定都不为空。并且,随着Right(v)的变大,Right(trans(v,x))也会变大。那么只有一段vp,…,ve的trans(v,x)=q。因为q已经被我们拆成了q和nq,且nq包含{L+1},那么就应该把vp,…,ve的trans(v,x)都改为nq。
至于ve以后的v,就不用改动了。你可能会问,不应该在剩下的trans(vi,x)的Right集合中插入{L+1}吗?
事实上,剩下的vi的trans(vi,x)一定是nq的祖先,而刚才nq中已经加入了L+1,则trans(vi,x)中就也加入了L+1,无需再改。
至此,算法结束。
步骤总结
设已经加入的串为T,长度为L,当前待添加字符为x。
令p=ST(T),即Right集合为{L}的状态。
新建np=ST(Tx),即Right集合为{L+1}的状态。
对p的所有trans(v,x)=null的祖先v,trans(v,x)=np。
令p的第一个trans(v,x)!=null的祖先为vp。若找不到这样的vp则Parent(np)=root并退出。
记q=trans(vp,x)。若Max(q)=Max(vp)+1,则Parent(np)=q并退出。
否则,新建结点nq,Parent(q)=Parent(np)=nq,Parent(nq)=原来的Parent(q),并且nq的转移函数拷贝q的。
对于所有为p的祖先且满足trans(v,x)=q的状态v,trans(v,x)=nq。
代码
SAM主要难在理解,代码其实非常短。
1
2
3
4
5
6
7
8
9
10
11
12
| void Extend(char c) {
int x = c - 'a', p = last, np = last = ++top;
mx[np] = mx[p] + 1; cnt[np] = 1;
for (; p && !ch[p][x]; p = fa[p]) ch[p][x] = np;
if (!p) { fa[np] = 1; return; }
int q = ch[p][x];
if (mx[q] == mx[p] + 1) { fa[np] = q; return; }
int nq = ++top; mx[nq] = mx[p] + 1;
fa[nq] = fa[q]; fa[q] = fa[np] = nq;
memcpy(ch[nq], ch[q], sizeof(ch[q]));
for (; ch[p][x] == q; p = fa[p]) ch[p][x] = nq;
}
|
代码中mx[]存储Max(s),fa[]存储Parent(s),cnt[]用来计算Right集合大小(构造完SAM后统计一下子树cnt之和即为Right集合大小)。
不存Min(s),是因为Min(s)=Max(fa)+1,不需要单独存。
其它部分就跟上面说的步骤差不多了。
后记
终于把论文抄完了……orzclj。